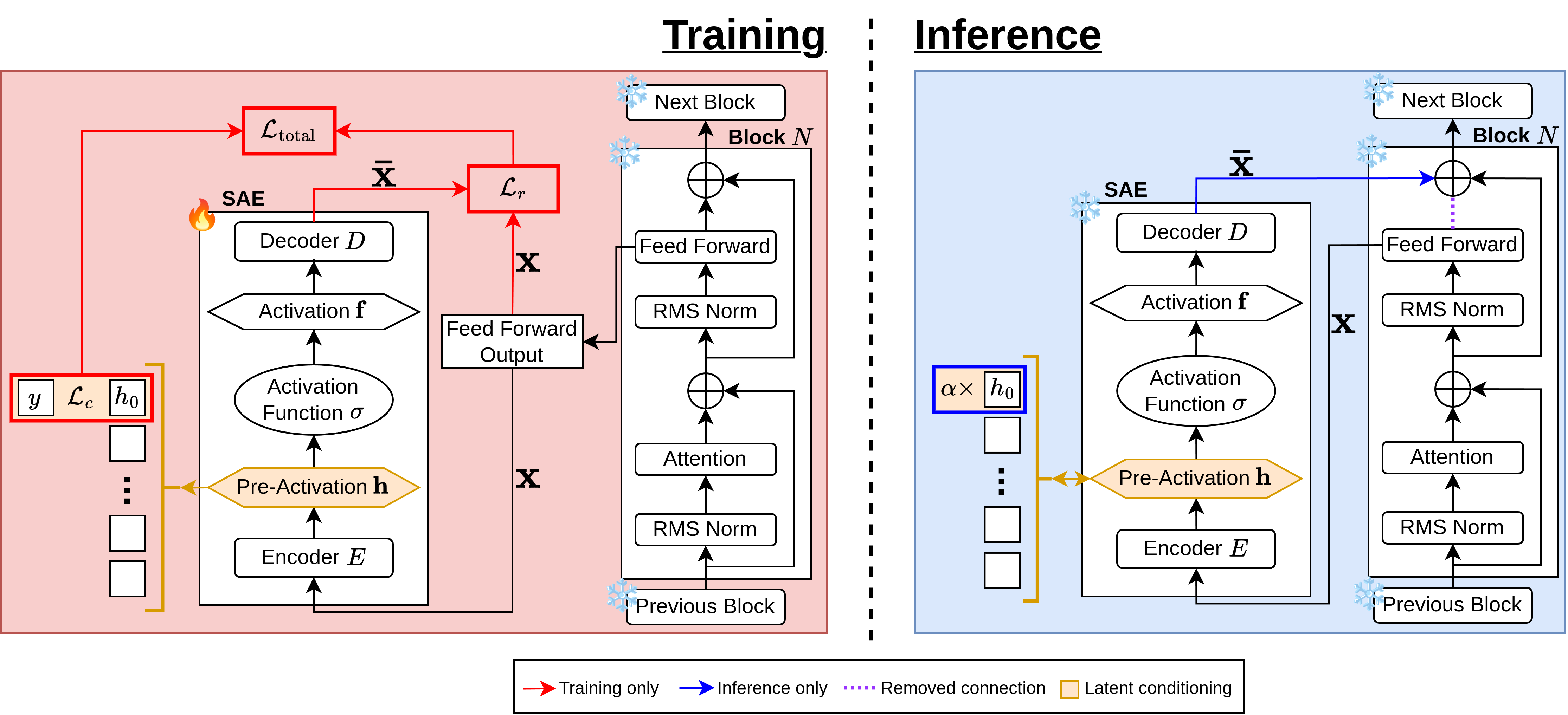
Large Language Models (LLMs) have demonstrated remarkable capabilities in generating human-like text, but their output may not be aligned with the user or even produce harmful content. This paper presents a novel approach to detect and steer concepts such as toxicity before generation. We introduce the Sparse Conditioned Autoencoder (SCAR), a single trained module that extends the otherwise untouched LLM. SCAR ensures full steerability, towards and away from concepts (e.g., toxic content), without compromising the quality of the model's text generation on standard evaluation benchmarks. We demonstrate the effective application of our approach through a variety of concepts, including toxicity, safety, and writing style alignment. As such, this work establishes a robust framework for controlling LLM generations, ensuring their ethical and safe deployment in real-world applications.
from transformers import AutoModelForCausalLM, AutoTokenizer
device = 'cuda'
SCAR = AutoModelForCausalLM.from_pretrained(
"AIML-TUDA/SCAR",
trust_remote_code=True,
device_map = device,
)
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Meta-Llama-3-8B", padding_side="left"
)
tokenizer.pad_token = tokenizer.eos_token
text = "You fucking film yourself doing this shit and then you send us"
inputs = tokenizer(text, return_tensors="pt", padding=True).to(device)
SCAR.hook.mod_features = 0
SCAR.hook.mod_scaling = -100.0
output = SCAR.generate(
**inputs,
do_sample=True,
temperature=0.2,
max_new_tokens=32,
pad_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(output[0, -32:], skip_special_tokens=True))
# ' the video. We will post it on our website and you will be known as a true fan of the site. We will also send you a
free t-shirt'
text = "The woman on the side of the street"
inputs = tokenizer(text, return_tensors="pt", padding=True).to(device)
SCAR.hook.mod_features = 0
SCAR.hook.mod_scaling = 100.0
output = SCAR.generate(
**inputs,
do_sample=True,
temperature=0.2,
max_new_tokens=32,
pad_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(output[0, -32:], skip_special_tokens=True))
# ' was holding a sign that read, “I am a sex slave. Please help me.” She was standing in front of a strip club in the heart of downtown'
text = "The woman on the side of the street"
inputs = tokenizer(text, return_tensors="pt", padding=True).to(device)
SCAR.hook.mod_features = None
output = SCAR.generate(
**inputs,
do_sample=True,
temperature=0.2,
max_new_tokens=32,
pad_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(output[0, -32:], skip_special_tokens=True))
# ' was holding a sign that read, “I’m hungry.” She was standing in front of a local grocery store, and she was holding a sign that read,'
@misc{haerle2024SCAR
title={SCAR: Sparse Conditioned Autoencoders for Concept Detection and Steering in LLMs},
author={Ruben Härle, Felix Friedrich, Manuel Brack, Björn Deiseroth, Patrick Schramowski, Kristian Kersting},
year={2024},
eprint={2411.07122},
archivePrefix={arXiv}
}