Building a Learner
We briefly demonstrate how we build a rule learner using alphaILP and show how to perform rule learning on visual scenes.
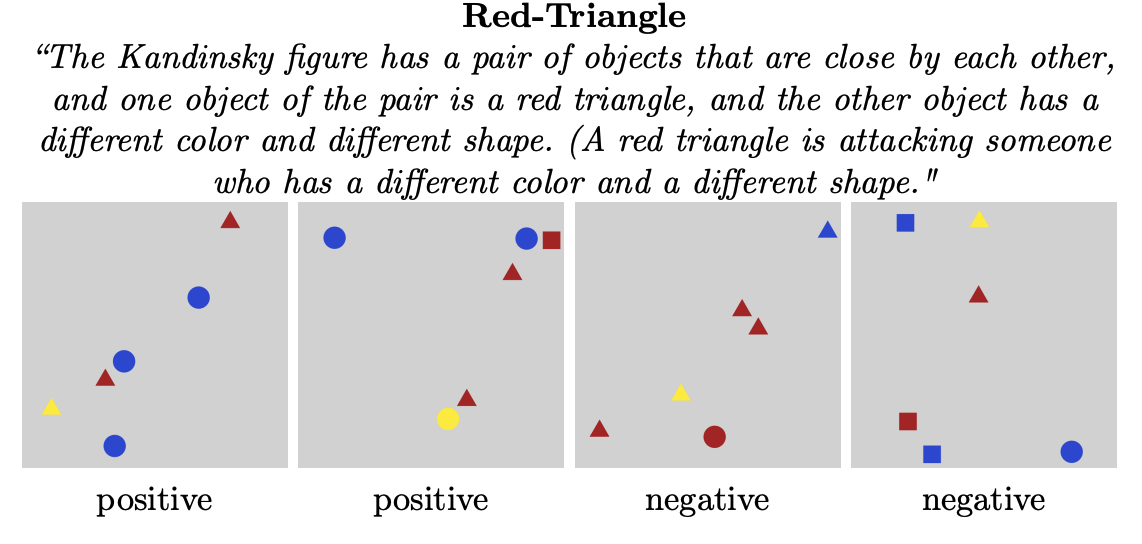
Solving Kandinsky Patterns
In this introduction, we solve the following kandinsky patterns:
from IPython.display import Image
Image('imgs/redtriangle_examples.png')
Lanuage Definition
To start writing logic programs, we need to specify a set of symbols we can use, which is called as language.
We define language in text files in
data/lang/dataset-type/dataset-name/. ### Predicates Predicates are
written in preds.txt file. The format is name:arity:data_types.
Each predicate should be specified line by line. For example,
kp:1:image
same_color_pair:2:object,object
same_shape_pair:2:object,object
diff_color_pair:2:object,object
diff_shape_pair:2:object,object
diff_color:2:color,color
diff_shape:2:shape,shape
Neural Predicates
Neural predicates are written in neural_preds.txt file. The format
is name:arity:data_types. Each predicate should be specified line by
line. For example,
in:2:object,image
color:2:object,color
shape:2:object,shape
Valuation functions for each neural predicate should be defined in
valuation_func.py and be registered in valuation.py.
Constants
Constants are written in consts.txt. The format is
data_type:names. Each constant should be specified line by line. For
example,
object:obj0,obj1,obj2,obj3,obj4
color:red,yellow,blue
shape:square,circle,triangle
image:img
The defined language can be loaded by logic_utils.get_lang.
# Load a defined language
import sys
sys.path.append('src/')
from src.logic_utils import get_lang
lark_path = 'src/lark/exp.lark'
lang_base_path = 'data/lang/'
lang, _clauses, bk_clauses, bk, atoms = get_lang(
lark_path, lang_base_path, 'kandinsky', 'twopairs')
Specify Hyperparameters
import torch
class Args:
dataset_type = 'kandinsky'
dataset = 'red-triangle'
batch_size = 2
batch_size_bs = 2 # batch size in the beam search step
num_objects = 2
no_cuda = True
num_workers = 4
program_size = 1
epochs = 20
lr = 1e-2
infer_step = 4
term_depth = 2
no_train = False
plot = False
small_data = False
t_beam = 6
n_beam = 20
n_max = 50
m = 1 # the number of clauses to be chosen
e = 6
args = Args()
device = torch.device('cpu')
Providing Background Knowledge
By using the defined symbols, you can write logic programs to provide background knowledge, for example,
same_shape_pair(X,Y):-shape(X,Z),shape(Y,Z).
same_color_pair(X,Y):-color(X,Z),color(Y,Z).
diff_shape_pair(X,Y):-shape(X,Z),shape(Y,W),diff_shape(Z,W).
diff_color_pair(X,Y):-color(X,Z),color(Y,W),diff_color(Z,W).
Clauses should be written in bk_clauses.txt.
An initial clause should be given in clauses.txt:
kp(X):-in(O1,X),in(O2,X).
# Write a logic program as text
clauses_str = """
kp(X):-in(O1,X),in(O2,X).
"""
# Parse the text to logic program
from fol.data_utils import DataUtils
du = DataUtils(lark_path, lang_base_path, args.dataset_type, args.dataset)
clauses = []
for line in clauses_str.split('\n')[1:-1]:
print(line)
clauses.append(du.parse_clause(line, lang))
clauses = [clauses[0]]
kp(X):-in(O1,X),in(O2,X).
Build a Reasoner
Import the neuro-symbolic forward reasoner.
from percept import SlotAttentionPerceptionModule, YOLOPerceptionModule
from valuation import SlotAttentionValuationModule, YOLOValuationModule
from facts_converter import FactsConverter
from nsfr import NSFReasoner
from logic_utils import build_infer_module, build_clause_infer_module
import torch
PM = YOLOPerceptionModule(e=args.num_objects, d=11, device=device)
VM = YOLOValuationModule(
lang=lang, device=device, dataset=args.dataset)
FC = FactsConverter(lang=lang, perception_module=PM,
valuation_module=VM, device=device)
IM = build_infer_module(clauses, bk_clauses, atoms, lang,
m=1, infer_step=args.infer_step, device=device, train=True)
CIM = build_clause_infer_module(clauses, bk_clauses, atoms, lang,
m=len(clauses), infer_step=args.infer_step, device=device)
# Neuro-Symbolic Forward Reasoner
NSFR = NSFReasoner(perception_module=PM, facts_converter=FC,
infer_module=IM, clause_infer_module=CIM, atoms=atoms, bk=bk, clauses=clauses)
Loading YOLO model...
Load Data
from nsfr_utils import get_data_loader, get_data_pos_loader # get torch data loader
import matplotlib.pyplot as plt
train_loader, val_loader, test_loader = get_data_loader(args)
# loading data loader for beam search using only positive examples
train_pos_loader, val_pos_loader, test_pos_loader = get_data_pos_loader(
args)
Build a Clause Generator
alphaILP performs beam-search to generate clauses.
from mode_declaration import get_mode_declarations
from clause_generator import ClauseGenerator
# Neuro-Symbolic Forward Reasoner for clause generation
NSFR_cgen = NSFReasoner(perception_module=PM, facts_converter=FC,
infer_module=IM, clause_infer_module=CIM, atoms=atoms, bk=bk, clauses=clauses)
mode_declarations = get_mode_declarations(args, lang, args.num_objects)
cgen = ClauseGenerator(args, NSFR_cgen, lang, val_pos_loader, mode_declarations,
bk_clauses, device=device) # torch.device('cpu'))
clauses = cgen.generate(
clauses, T_beam=args.t_beam, N_beam=args.n_beam, N_max=args.n_max)
Weight Learning
Using the generated clauses in beam-search, we perform weight learning from positive and negative examples.
from nsfr_utils import get_nsfr_model
# update
NSFR = get_nsfr_model(args, lang, clauses, atoms, bk,bk_clauses, device, train=True)
Loading YOLO model...
# prepare an optimizer
params = NSFR.get_params()
optimizer = torch.optim.RMSprop(params, lr=args.lr)
from tqdm.notebook import tqdm
from nsfr_utils import get_prob
bce = torch.nn.BCELoss()
loss_list = []
for epoch in range(args.epochs):
loss_i = 0
for i, sample in tqdm(enumerate(train_loader, start=0)):
# to cuda
imgs, target_set = map(lambda x: x.to(device), sample)
# infer and predict the target probability
V_T = NSFR(imgs)
# NSFR.print_valuation_batch(V_T)
predicted = get_prob(V_T, NSFR, args)
loss = bce(predicted, target_set)
loss_i += loss.item()
loss.backward()
optimizer.step()
loss_list.append(loss_i)
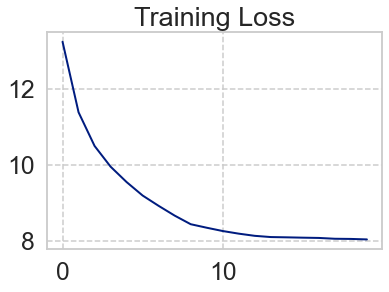
print(loss_i)
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
%matplotlib inline
sns.set()
sns.set_style("whitegrid", {'grid.linestyle': '--'})
sns.set_context("paper", 1.5, {"lines.linewidth": 4})
sns.set_palette("winter_r", 8, 1)
sns.set('talk', 'whitegrid', 'dark', font_scale=1.5,
rc={"lines.linewidth": 2, 'grid.linestyle': '--'})
xs = list(range(len(loss_list)))
plt.plot(np.array(xs), np.array(loss_list))
plt.title('Training Loss')
plt.show()
NSFR.print_program()
====== LEARNED PROGRAM ======
Ws_softmaxed: [[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.1 0 0 0.34 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.2 0.09 0 0
0 0 0 0 0 0 0 0 0 0 0.28 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0]]
C_0: kp(X):-closeby(O1,O2),color(O2,red),diff_color_pair(O1,O2),in(O1,X),in(O2,X),shape(O2,triangle). 0.34